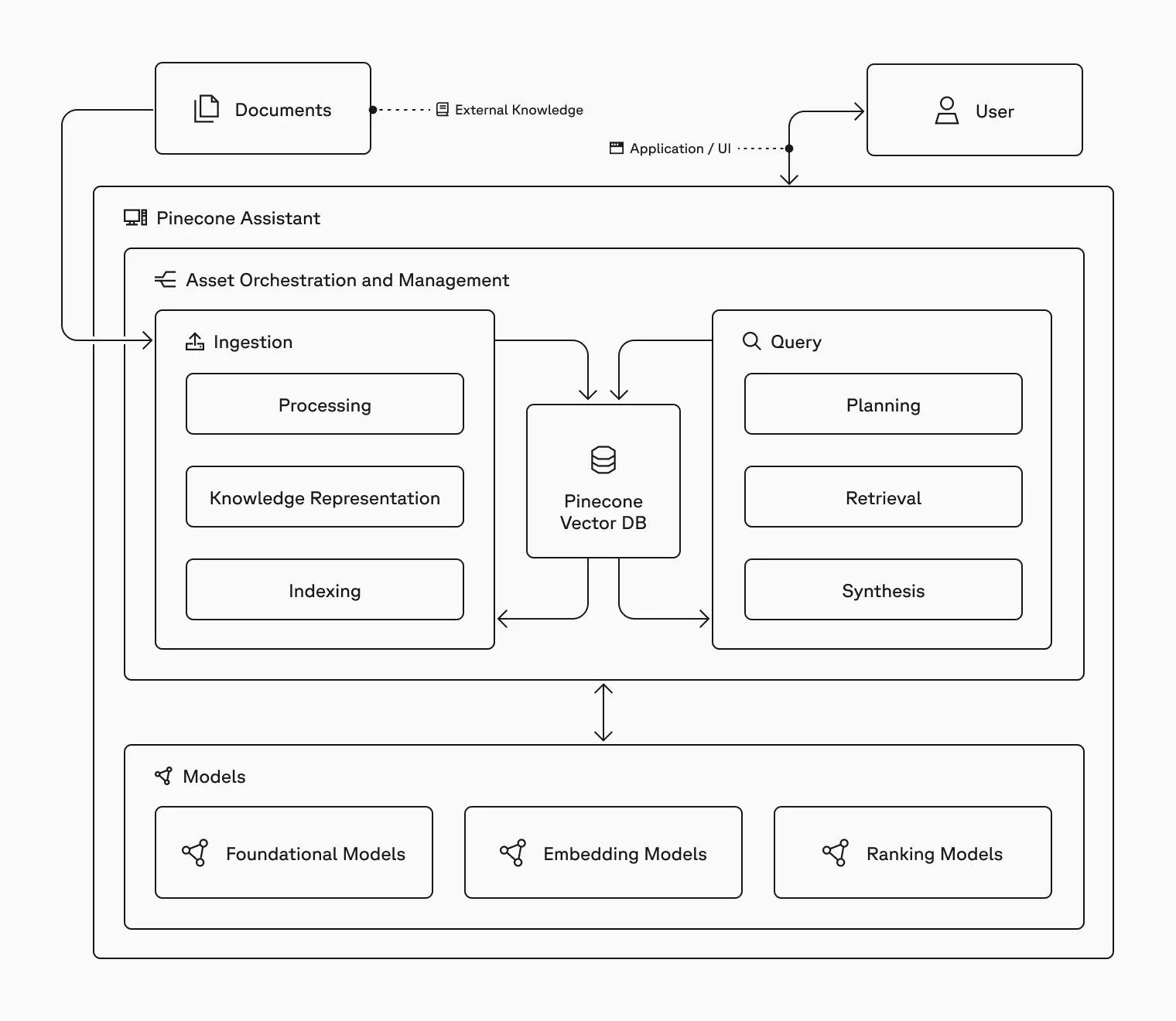
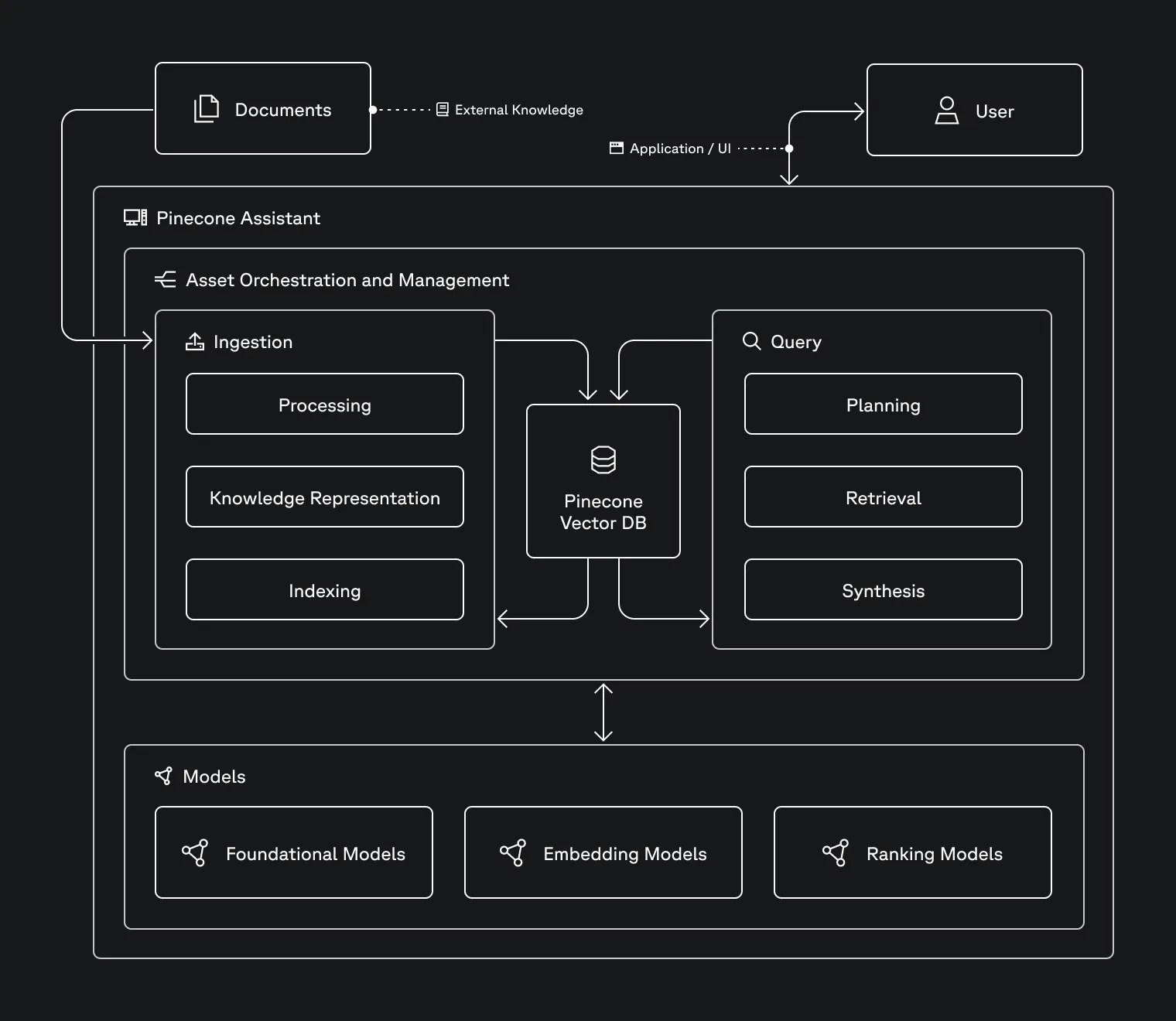
Overview
Pinecone Assistant runs as a managed service on the Pinecone platform. It uses a combination of machine learning models and information retrieval techniques to provide responses that are informed by your documents. The assistant is designed to be easy to use, requiring minimal setup and no machine learning expertise. Pinecone Assistant simplifies complex tasks like data chunking, vector search, embedding, and querying while ensuring privacy and security.