Hugging Face Inference Endpoints offers a secure production solution to easily deploy any Hugging Face Transformers, Sentence-Transformers and Diffusion models from the Hub on dedicated and autoscaling infrastructure managed by Hugging Face.
Coupled with Pinecone, you can use Hugging Face to generate and index high-quality vector embeddings with ease.
Setup guide
Hugging Face Inference Endpoints allows access to straightforward model inference. Coupled with Pinecone we can generate and index high-quality vector embeddings with ease.
Let’s get started by initializing an Inference Endpoint for generating vector embeddings.
Create an endpoint
We start by heading over to the Hugging Face Inference Endpoints homepage and signing up for an account if needed. After, we should find ourselves on this page:
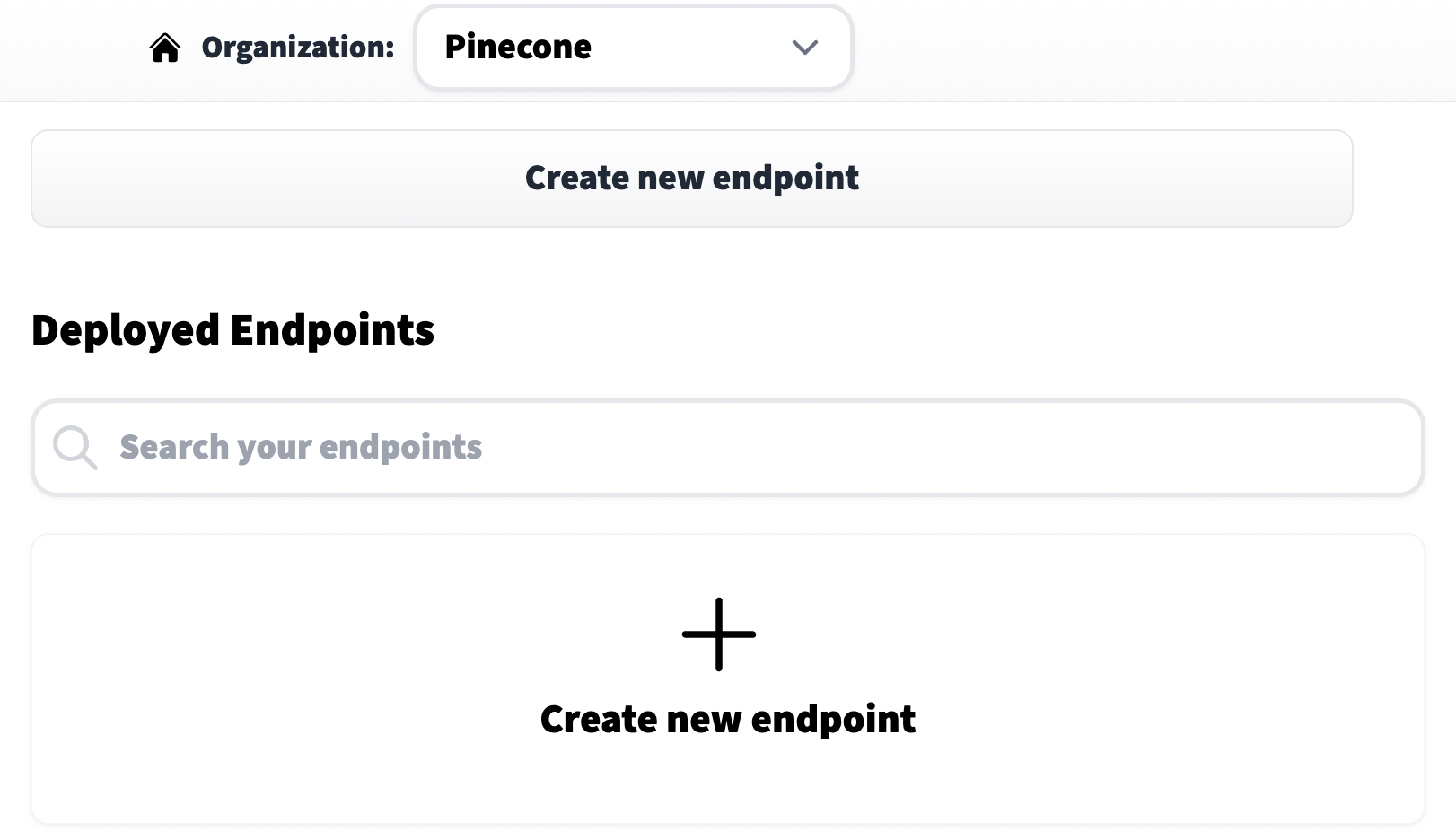 We click on Create new endpoint, choose a model repository (eg name of the model), endpoint name (this can be anything), and select a cloud environment. Before moving on it is very important that we set the Task to Sentence Embeddings (found within the Advanced configuration settings).
We click on Create new endpoint, choose a model repository (eg name of the model), endpoint name (this can be anything), and select a cloud environment. Before moving on it is very important that we set the Task to Sentence Embeddings (found within the Advanced configuration settings).
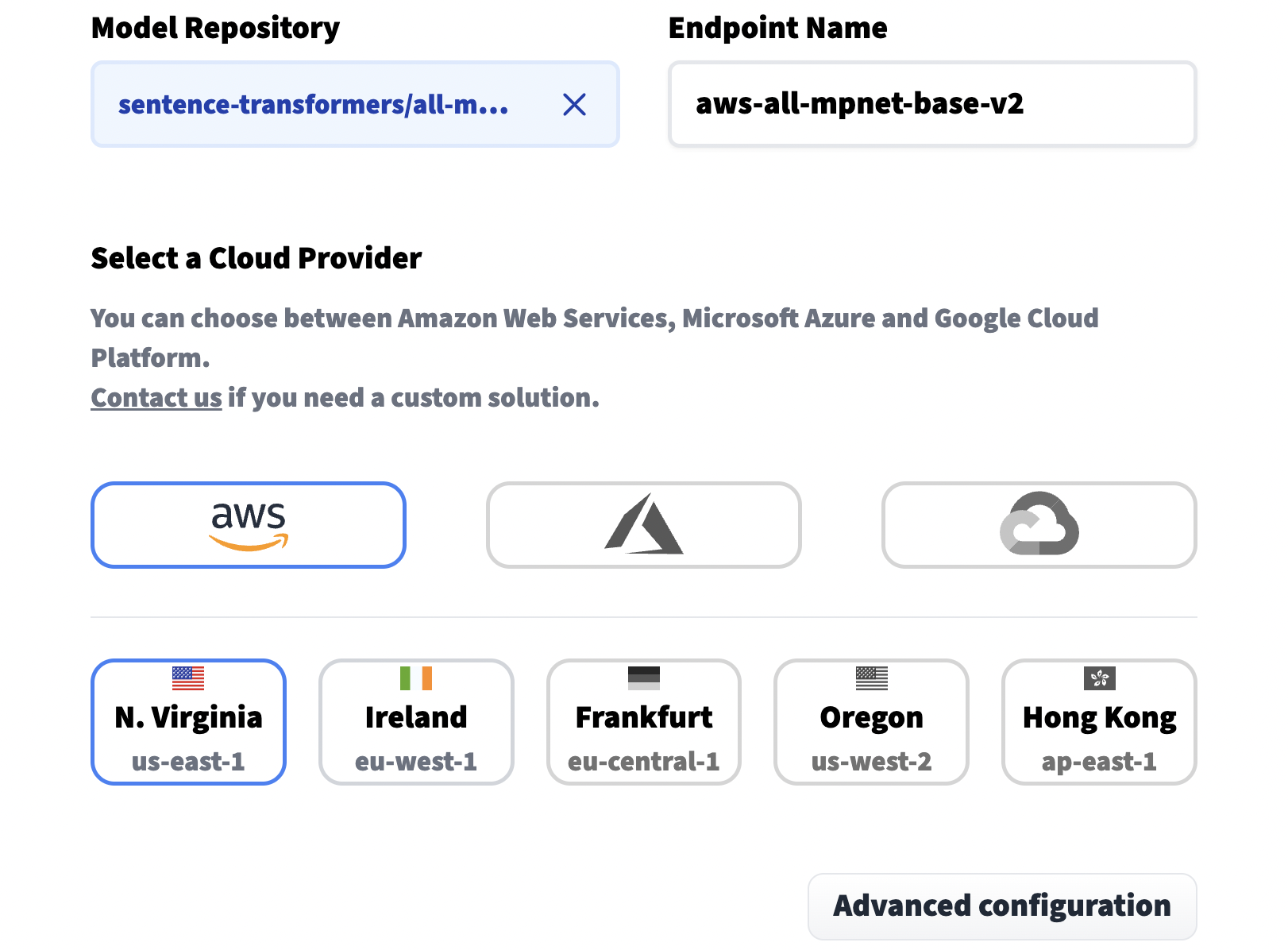
 Other important options include the Instance Type, by default this uses CPU which is cheaper but also slower. For faster processing we need a GPU instance. And finally, we set our privacy setting near the end of the page.
After setting our options we can click Create Endpoint at the bottom of the page. This action should take use to the next page where we will see the current status of our endpoint.
Other important options include the Instance Type, by default this uses CPU which is cheaper but also slower. For faster processing we need a GPU instance. And finally, we set our privacy setting near the end of the page.
After setting our options we can click Create Endpoint at the bottom of the page. This action should take use to the next page where we will see the current status of our endpoint.
 Once the status has moved from Building to Running (this can take some time), we’re ready to begin creating embeddings with it.
Once the status has moved from Building to Running (this can take some time), we’re ready to begin creating embeddings with it.
Create embeddings
Each endpoint is given an Endpoint URL, it can be found on the endpoint Overview page. We need to assign this endpoint URL to the endpoint_url variable.
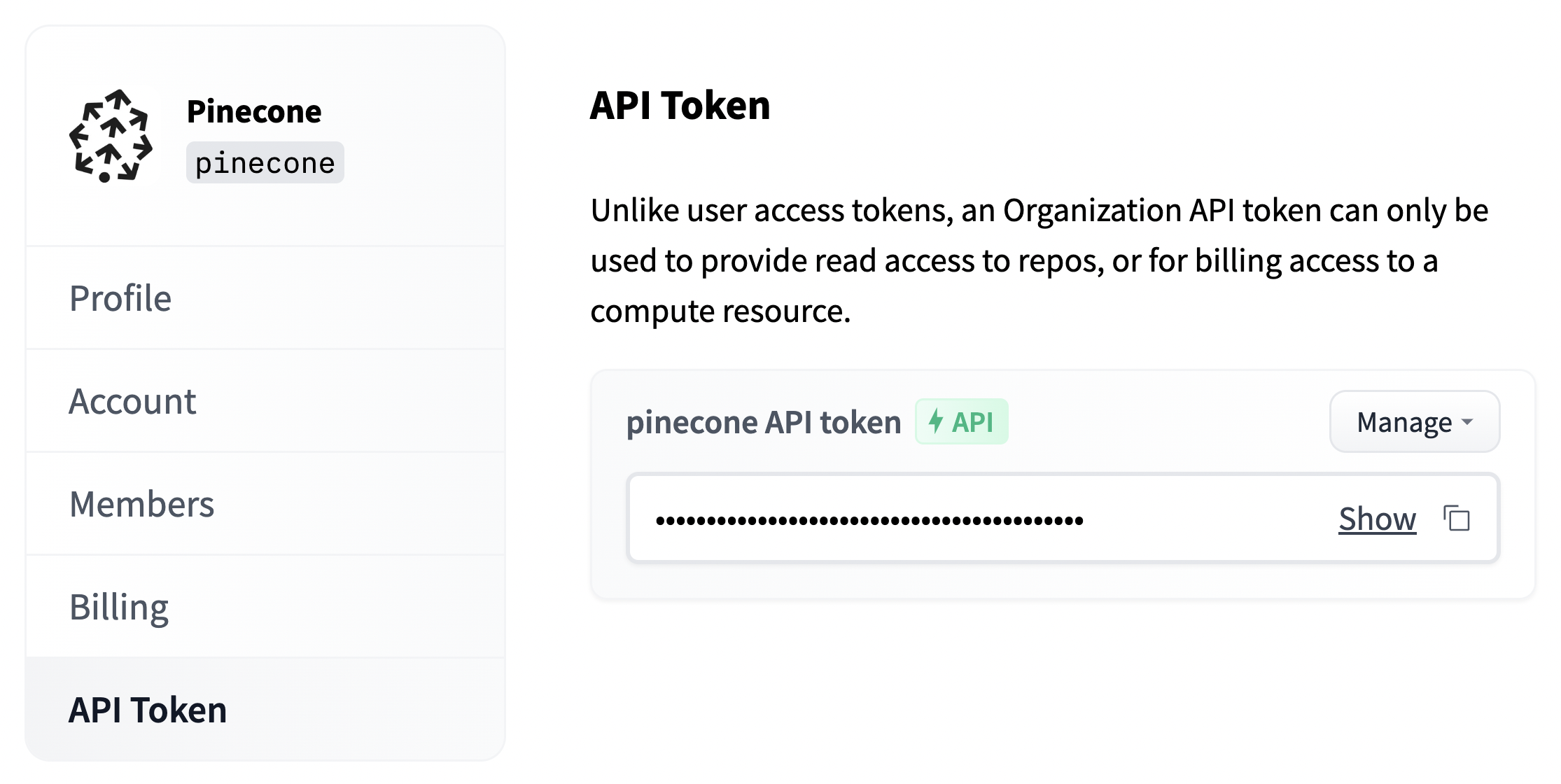
 We will also need the organization API token, we find this via the organization settings on Hugging Face (
We will also need the organization API token, we find this via the organization settings on Hugging Face (https://huggingface.co/organizations/<ORG_NAME>/settings/profile). This is assigned to the api_org variable.
 Now we’re ready to create embeddings via Inference Endpoints. Let’s start with a toy example.
We should see a
Now we’re ready to create embeddings via Inference Endpoints. Let’s start with a toy example.
We should see a 200 response.
Inside the response we should find two embeddings…
We can also see the dimensionality of our embeddings like so:
We will need more than two items to search through, so let’s download a larger dataset. For this we will use Hugging Face datasets.
SNLI contains 550K sentence pairs, many of these include duplicate items so we will take just one set of these (the hypothesis) and deduplicate them.
We will drop to 50K sentences so that the example is quick to run, if you have time, feel free to keep the full 480K.
Create a Pinecone index
With our endpoint and dataset ready, all that we’re missing is a vector database. For this, we need to initialize our connection to Pinecone, this requires a free API key.
Now we create a new index called 'hf-endpoints', the name isn’t important but the dimension must align to our endpoint model output dimensionality (we found this in dim above) and the model metric (typically cosine is okay, but not for all models).
Create and index embeddings
Now we have all of our components ready; endpoints, dataset, and Pinecone. Let’s go ahead and create our dataset embeddings and index them within Pinecone.
With everything indexed we can begin querying. We will take a few examples from the premise column of the dataset.
These look good, let’s try a couple more examples.
And one more…
All of these results look excellent. If you are not planning on running your endpoint and vector DB beyond this tutorial, you can shut down both.
Clean up
Shut down the endpoint by navigating to the Inference Endpoints Overview page and selecting Delete endpoint. Delete the Pinecone index with:
Once the index is deleted, you cannot use it again.