Setup guide
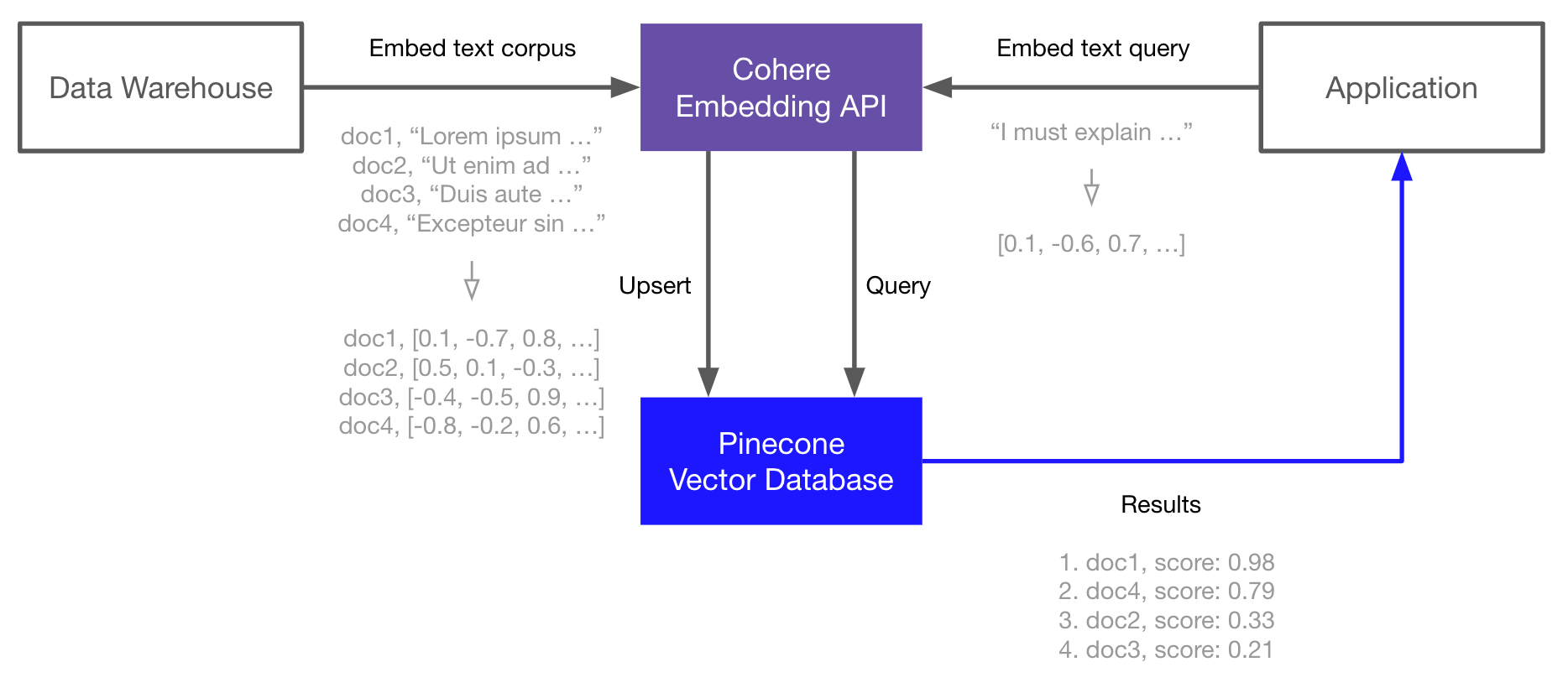
View source Open in Colab In this guide, you will learn how to use the Cohere Embed API endpoint to generate language embeddings, and then index those embeddings in the Pinecone vector database for fast and scalable vector search. This is a powerful and common combination for building semantic search, question-answering, threat-detection, and other applications that rely on NLP and search over a large corpus of text data. The basic workflow looks like this:- Embed and index
- Use the Cohere Embed API endpoint to generate vector embeddings of your documents (or any text data).
- Upload those vector embeddings into Pinecone, which can store and index millions/billions of these vector embeddings, and search through them at ultra-low latencies.
- Search
- Pass your query text or document through the Cohere Embed API endpoint again.
- Take the resulting vector embedding and send it as a query to Pinecone.
- Get back semantically similar documents, even if they don’t share any keywords with the query.
Set up the environment
Start by installing the Cohere and Pinecone clients and HuggingFace Datasets for downloading the TREC dataset used in this guide:Shell
Create embeddings
Sign up for an API key at Cohere and then use it to initialize your connection.Python
Python
trec contains two label features and the text feature. Pass the questions from the text feature to Cohere to create embeddings.
Python
Python
1024 embedding dimensionality produced by Cohere’s embed-english-v3.0 model, and the 1000 samples you built embeddings for.
Store the Embeddings
Now that you have your embeddings, you can move on to indexing them in the Pinecone vector database. For this, you need a Pinecone API key. You first initialize our connection to Pinecone and then create a new index calledcohere-pinecone-trec for storing the embeddings. When creating the index, you specify that you would like to use the cosine similarity metric to align with Cohere’s embeddings, and also pass the embedding dimensionality of 1024.
Python
Python
index.describe_index_stats that you have a 1024-dimensionality index populated with 1000 embeddings. For serverless on-demand indexes, the index_fullness metric is typically 0 because storage and compute scale automatically. If you’re using dedicated read nodes, index_fullness (along with memory_fullness and storage_fullness) tells you how close the index is to its allocated capacity.
Semantic search
Now that you have your indexed vectors, you can perform a few search queries. When searching, you will first embed your query using Cohere, and then search using the returned vector in Pinecone.Python
metadata field. Let’s print out the top_k most similar questions and their respective similarity scores.
Python
Python
Python