Indexes
In Pinecone, you store vector data in indexes. There are two types of indexes: dense and sparse.Dense indexes
Dense indexes store dense vectors, which are a series of numbers that represent the meaning and relationships of text, images, or other types of data. Each number in a dense vector corresponds to a point in a multidimensional space. Vectors that are closer together in that space are semantically similar. When you query a dense index, Pinecone retrieves the dense vectors that are the most semantically similar to the query. This is often called semantic search, nearest neighbor search, similarity search, or just vector search. Learn more:Sparse indexes
Sparse indexes store sparse vectors, which are a series of numbers that represent the words or phrases in a document. Sparse vectors have a very large number of dimensions, where only a small proportion of values are non-zero. The dimensions represent words from a dictionary, and the values represent the importance of these words in the document. When you search a sparse index, Pinecone retrieves the sparse vectors that most exactly match the words or phrases in the query. Query terms are scored independently and then summed, with the most similar records scored highest. This is often called lexical search or keyword search. Learn more:Limitations
Sparse indexes have the following limitations:- Max non-zero values per sparse vector: 1000
- Max upserts per second per sparse index: 10
- Max queries per second per sparse index: 100
-
Max
top_kvalue per query: 1000You may get fewer thantop_kresults iftop_kis larger than the number of sparse vectors in your index that match your query. That is, any vectors where the dotproduct score is0will be discarded. - Max query results size: 4MB
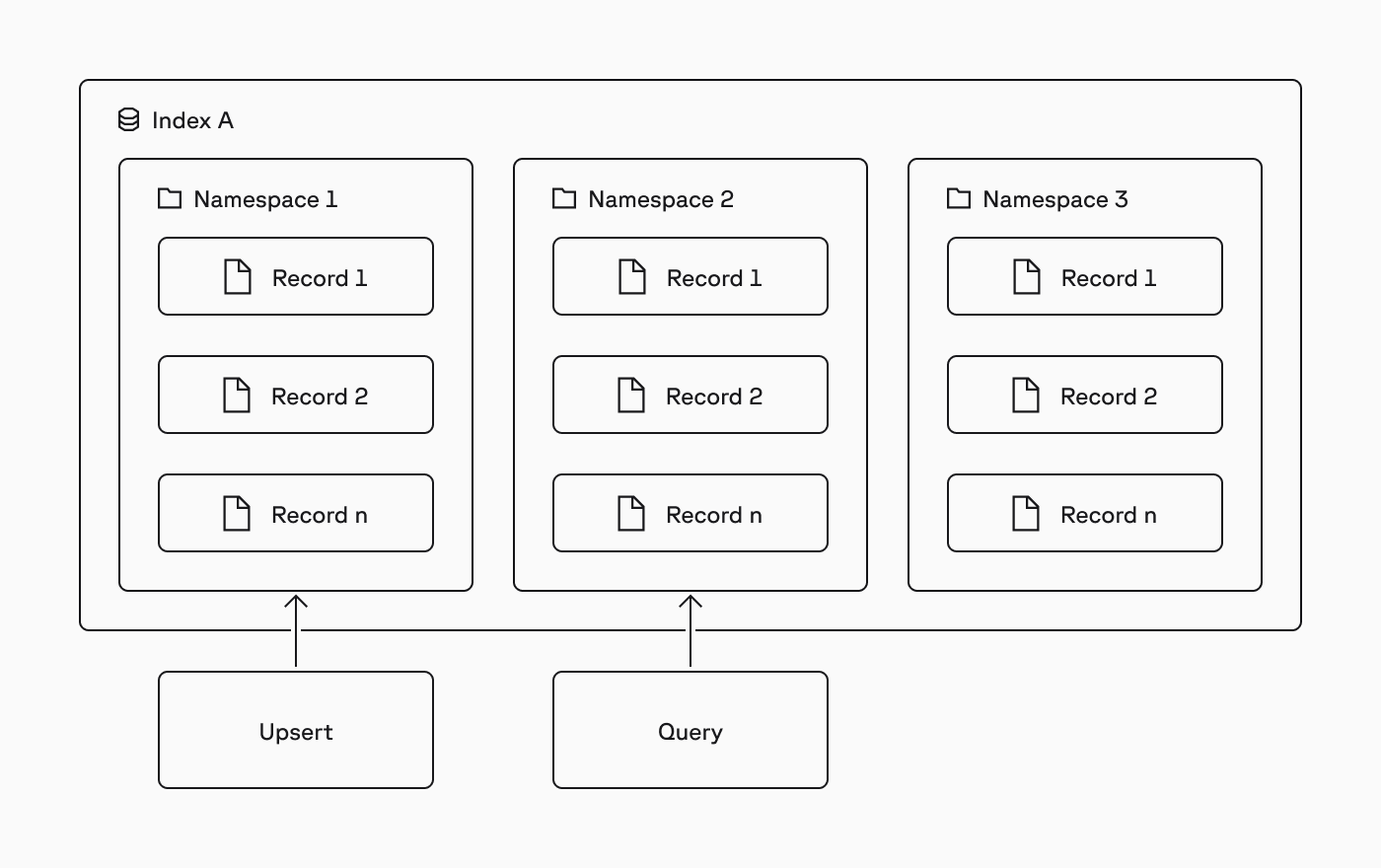
Namespaces
Within an index, records are partitioned into namespaces, and all upserts, queries, and other data operations always target one namespace. This has two main benefits:- Multitenancy: When you need to isolate data between customers, you can use one namespace per customer and target each customer’s writes and queries to their dedicated namespace. See Implement multitenancy for end-to-end guidance.
- Faster queries: When you divide records into namespaces in a logical way, you speed up queries by ensuring only relevant records are scanned. The same applies to fetching records, listing record IDs, and other data operations.
While the Standard and Enterprise plans support up to 100,000 namespaces per index, Pinecone can accommodate million-scale namespaces and beyond for specific use cases. If your application requires more than 100,000 namespaces, contact Support.

Vector embedding
Dense vectors and sparse vectors are the basic units of data in Pinecone and what Pinecone was specially designed to store and work with. Dense vectors represents the semantics of data such as text, images, and audio recordings, while sparse vectors represent documents or queries in a way that captures keyword information. To transform data into vector format, you use an embedding model. You can either use Pinecone’s integrated embedding models to convert your source data to vectors automatically, or you can use an external embedding model and bring your own vectors to Pinecone.Integrated embedding
- Create an index that is integrated with one of Pinecone’s hosted embedding models.
- Upsert your source text. Pinecone uses the integrated model to convert the text to vectors automatically.
- Search with a query text. Again, Pinecone uses the integrated model to convert the text to a vector automatically.
Bring your own vectors
- Use an embedding model to convert your text to vectors. The model can be hosted by Pinecone or an external provider.
- Create an index that matches the characteristics of the model.
- Upsert your vectors directly.
- Use the same external embedding model to convert a query to a vector.
- Search with your query vector directly.
Data ingestion
There are two ways to ingest data into an index:- Importing from object storage is the most efficient and cost-effective way to load large numbers of records into an index. You store your data as Parquet files in object storage, integrate your object storage with Pinecone, and then start an asynchronous, long-running operation that imports and indexes your records.
- Upserting is intended for ongoing writes to an index. Batch upserting can improve throughput performance and is a good option for larger numbers of records (up to 1000 per batch) if you cannot work around import’s current limitations.
Metadata
Every record in an index must contain an ID and a vector. In addition, you can include metadata key-value pairs to store additional information or context. When you query the index, you can then include a metadata filter to limit the search to records matching a filter expression. Searches without metadata filters do not consider metadata and search the entire namespace.Metadata format
- Metadata fields must be key-value pairs in a flat JSON object. Nested JSON objects are not supported.
- Keys must be strings and must not start with a
$. - Values must be one of the following data types:
- String
- Integer (converted to a 64-bit floating point by Pinecone)
- Floating point
- Boolean (
true,false) - List of strings
- Null metadata values aren’t supported. Instead of setting a key to
null, remove the key from the metadata payload.
Metadata size
Pinecone supports 40KB of metadata per record.Metadata filter expressions
Pinecone’s filtering language supports the following operators:| Operator | Function | Supported types |
|---|---|---|
$eq | Matches with metadata values that are equal to a specified value. Example: {"genre": {"$eq": "documentary"}} | Number, string, boolean |
$ne | Matches with metadata values that are not equal to a specified value. Example: {"genre": {"$ne": "drama"}} | Number, string, boolean |
$gt | Matches with metadata values that are greater than a specified value. Example: {"year": {"$gt": 2019}} | Number |
$gte | Matches with metadata values that are greater than or equal to a specified value. Example:{"year": {"$gte": 2020}} | Number |
$lt | Matches with metadata values that are less than a specified value. Example: {"year": {"$lt": 2020}} | Number |
$lte | Matches with metadata values that are less than or equal to a specified value. Example: {"year": {"$lte": 2020}} | Number |
$in | Matches with metadata values that are in a specified array. Example: {"genre": {"$in": ["comedy", "documentary"]}} | String, number |
$nin | Matches with metadata values that are not in a specified array. Example: {"genre": {"$nin": ["comedy", "documentary"]}} | String, number |
$exists | Matches with the specified metadata field. Example: {"genre": {"$exists": true}} | Number, string, boolean |
$and | Joins query clauses with a logical AND. Example: {"$and": [{"genre": {"$eq": "drama"}}, {"year": {"$gte": 2020}}]} | - |
$or | Joins query clauses with a logical OR. Example: {"$or": [{"genre": {"$eq": "drama"}}, {"year": {"$gte": 2020}}]} | - |
Only
$and and $or are allowed at the top level of the query expression.Each
$in or $nin operator accepts a maximum of 10,000 values. Exceeding this limit will cause the request to fail. For more information, see Metadata filter limits."genre" metadata field with a list of strings:
JSON
"genre" takes on both values, and requests with the following filters will match:
JSON
JSON
JSON
JSON