Setup guide
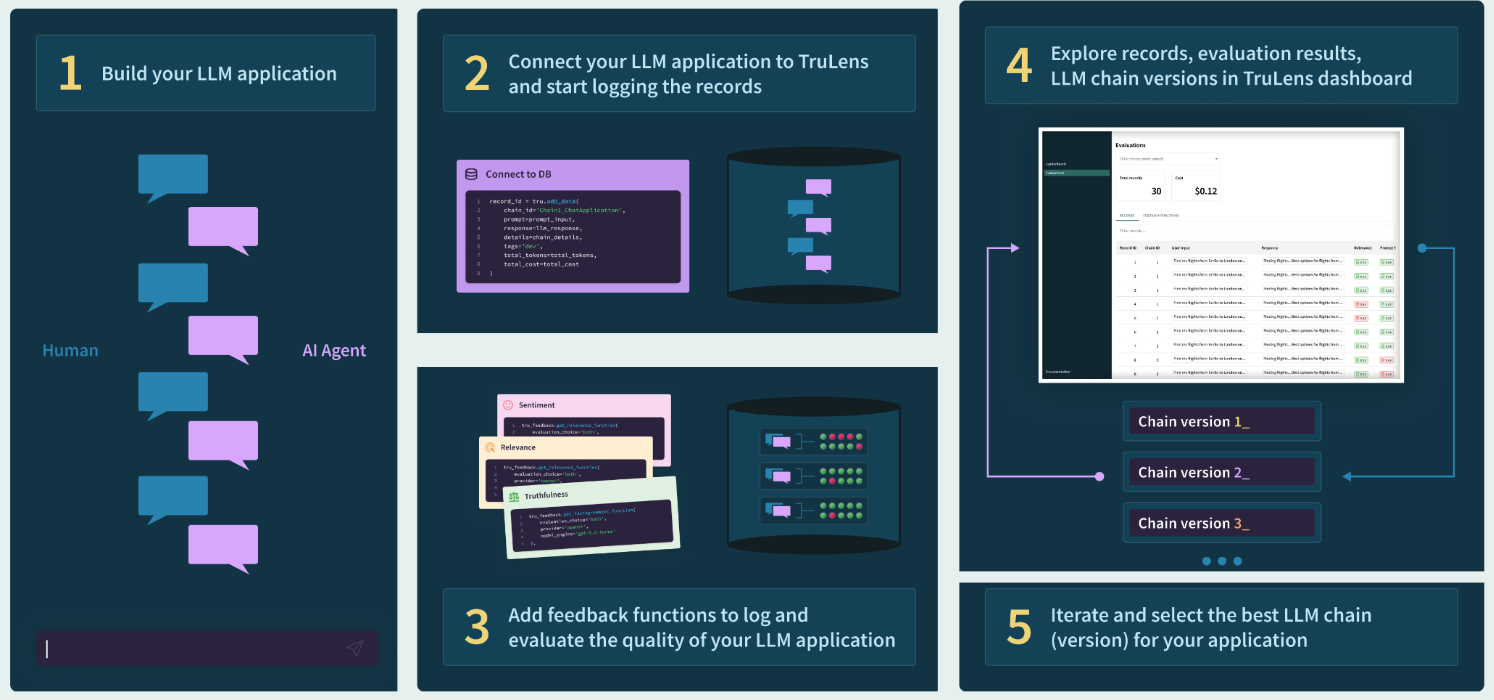
TruLens is a powerful open source library for evaluating and tracking large language model-based applications. In this guide, we will show you how to use TruLens to evaluate applications built on top of a high performance Pinecone vector database.Why TruLens?
Systematic evaluation is needed to support reliable, non-hallucinatory LLM-based applications. TruLens contains instrumentation and evaluation tools for large language model (LLM)-based applications. For evaluation, TruLens provides a set of feedback functions, analogous to labeling functions, to programmatically score the input, output and intermediate text of an LLM app. Each LLM application request can be scored on its question-answer relevance, context relevance and groundedness. These feedback functions provide evidence that your LLM-application is non-hallucinatory.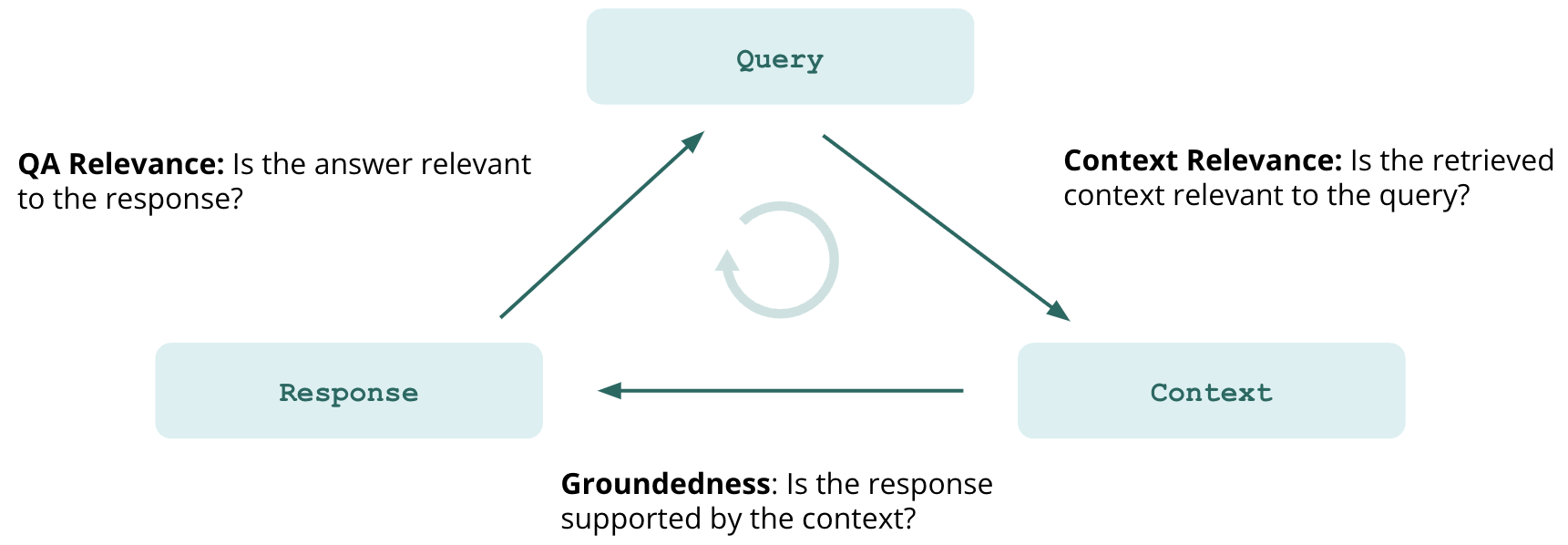
Why Pinecone?
Large language models alone have a hallucination problem. Several decades of machine learning research have optimized models, including modern LLMs, for generalization, while actively penalizing memorization. However, many of today’s applications require factual, grounded answers. LLMs are also expensive to train, and provided by third party APIs. This means the knowledge of an LLM is fixed. Retrieval-augmented generation (RAG) is a way to reliably ensure models are grounded, with Pinecone as the curated source of real world information, long term memory, application domain knowledge, or whitelisted data. In the RAG paradigm, rather than just passing a user question directly to a language model, the system retrieves any documents that could be relevant in answering the question from the knowledge base, and then passes those documents (along with the original question) to the language model to generate the final response. The most popular method for RAG involves chaining together LLMs with vector databases, such as the widely used Pinecone vector DB. In this process, a numerical vector (an embedding) is calculated for all documents, and those vectors are then stored in a database optimized for storing and querying vectors. Incoming queries are vectorized as well, typically using an encoder LLM to convert the query into an embedding. The query embedding is then matched via embedding similarity against the document embeddings in the vector database to retrieve the documents that are relevant to the query.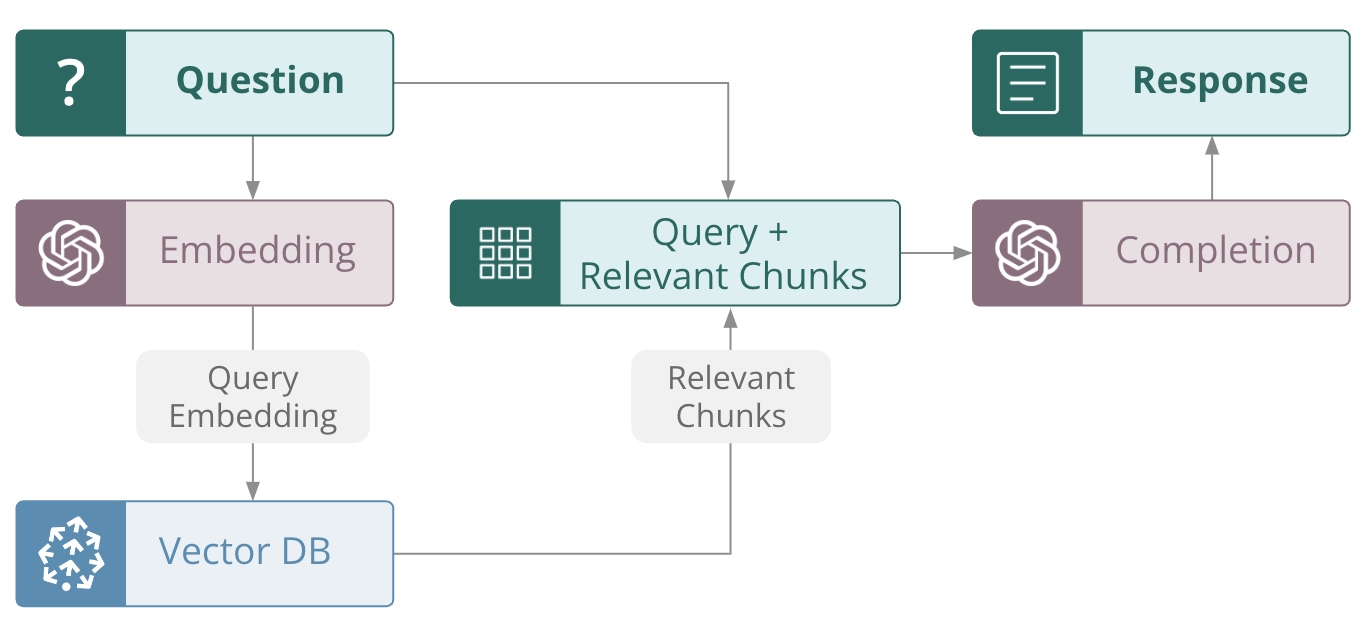
In addition, Pinecone is fully managed, so it is easy to change configurations and components. Combined with the tracking and evaluation with TruLens, this is a powerful combination that enables fast iteration of your application.
Using Pinecone and TruLens to improve LLM performance and reduce hallucination
To build an effective RAG-style LLM application, it is important to experiment with various configuration choices while setting up the vector database, and study their impact on performance metrics. In this example, we explore the downstream impact of some of these configuration choices on response quality, cost and latency with a sample LLM application built with Pinecone as the vector DB. The evaluation and experiment tracking is done with the TruLens open source library. TruLens offers an extensible set of feedback functions to evaluate LLM apps and enables developers to easily track their LLM app experiments. In each component of this application, different configuration choices can be made that can impact downstream performance. Some of these choices include the following: Constructing the Vector DB- Data preprocessing and selection
- Chunk Size and Chunk Overlap
- Index distance metric
- Selection of embeddings
- Amount of context retrieved (top k)
- Query planning
- Prompting
- Model choice
- Model parameters (size, temperature, frequency penalty, model retries, etc.)
Creating the index in Pinecone
Here we’ll download a pre-embedded dataset from thepinecone-datasets library allowing us to skip the embedding and preprocessing steps.
Python
Python
Python
Build the vector store
Now that we’ve built our index, we can start using LangChain to initialize our vector store.Python
vectorstore.
Initialize our RAG application
To do this, we initialize aRetrievalQA as our app:
Python
TruLens for evaluation and tracking of LLM experiments
Once we’ve set up our app, we should put together our feedback functions. As a reminder, feedback functions are an extensible method for evaluating LLMs. Here we’ll set up two feedback functions:qs_relevance and qa_relevance. They’re defined as follows:
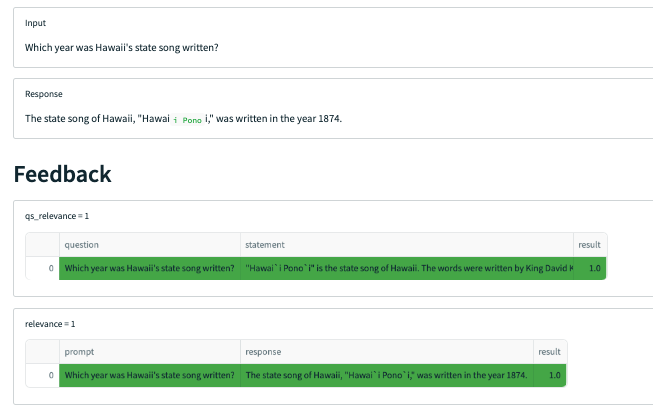
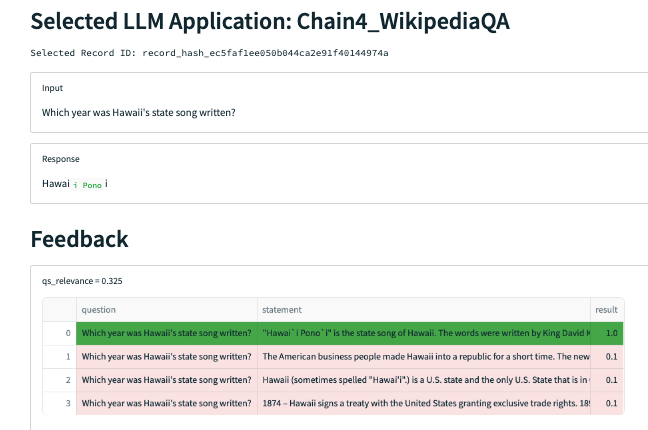
QS Relevance: query-statement relevance is the average of relevance (0 to 1) for each context chunk returned by the semantic search.
QA Relevance: question-answer relevance is the relevance (again, 0 to 1) of the final answer to the original question.
Python
.on_input_output() to specify that the feedback function should be applied on both the input and output of the application.
For QS Relevance, we use TruLens selectors to locate the context chunks retrieved by our application. Let’s break it down into simple parts:
-
Argument Specification – The
on_inputwhich appears first is a convenient shorthand and states that the first argument toqs_relevance(the question) is to be the main input of the app. -
Argument Specification – The
on(Select...)line specifies where the statement argument to the implementation comes from. We want to evaluate the context chunks, which are an intermediate step of the LLM app. This form references the langchain app object call chain, which can be viewed fromtru.run_dashboard(). This flexibility allows you to apply a feedback function to any intermediate step of your LLM app. Below is an example where TruLens displays how to select each piece of the context.
-
Aggregation specification — The last line aggregate (
np.mean) specifies how feedback outputs are to be aggregated. This only applies to cases where the argument specification names more than one value for an input or output.
f_qs_relevance can be now be run on apps/records and will automatically select the specified components of those apps/records
To finish up, we just wrap our Retrieval QA app with TruLens along with a list of the feedback functions we will use for eval.
Python
Python

Experiment with distance metrics
Now that we’ve walked through the process of building our tracked RAG application using cosine as the distance metric, all we have to do for the next two experiments is to rebuild the index witheuclidean or dotproduct as the metric and follow the rest of the steps above as is.
Because we are using OpenAI embeddings, which are normalized to length 1, dot product and cosine distance are equivalent - and Euclidean will also yield the same ranking. See the OpenAI docs for more information. With the same document ranking, we should not expect a difference in response quality, but computation latency may vary across the metrics. Indeed, OpenAI advises that dot product computation may be a bit faster than cosine. We will be able to confirm this expected latency difference with TruLens.
Python
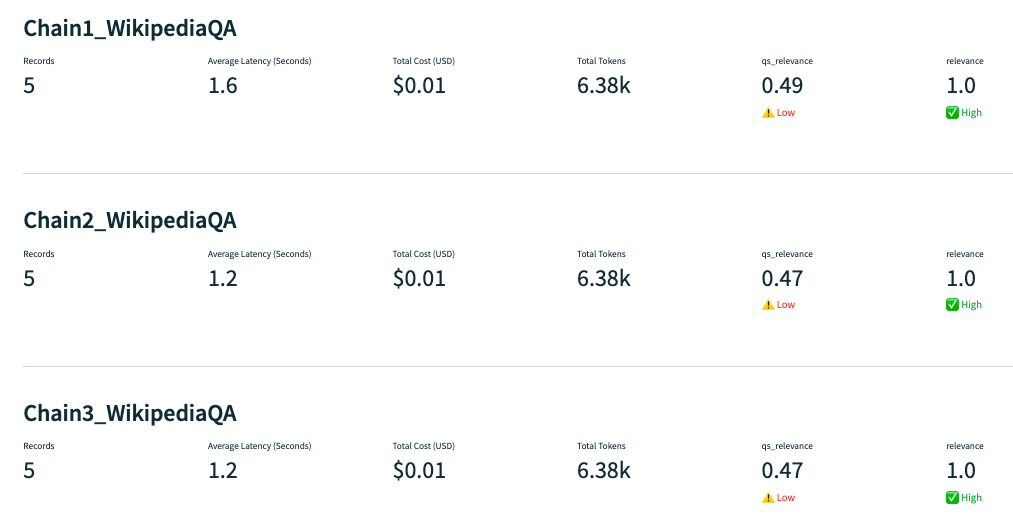
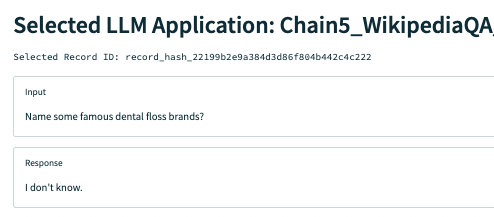
Problem: hallucination
Digging deeper into the Query Statement Relevance, we notice one problem in particular with a question about famous dental floss brands. The app responds correctly, but is not backed up by the context retrieved, which does not mention any specific brands.
Quickly evaluate app components with LangChain and TruLens
Using a less powerful model is a common way to reduce hallucination for some applications. We’ll evaluate ada-001 in our next experiment for this purpose.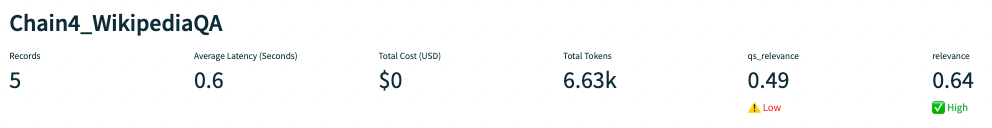
text-ada-001 from the LangChain LLM store. Adding in easy evaluation with TruLens allows us to quickly iterate through different components to find our optimal app configuration.
Python
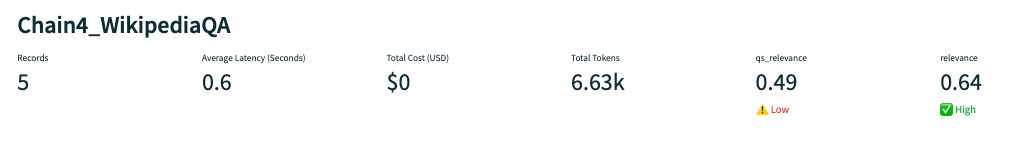
top_k, or the number of context chunks retrieved by the semantic search, may help.
We can do so as follows:
Python
top_k is implemented in LangChain’s RetrievalQA is that the documents are still retrieved by semantic search and only the top_k are passed to the LLM. Therefore, TruLens also captures all of the context chunks that are being retrieved. In order to calculate an accurate QS Relevance metric that matches what’s being passed to the LLM, we only calculate the relevance of the top context chunk retrieved by slicing the input_documents passed into the TruLens Select function:
Python
qs_relevance, qa_relevance and latency!