Setup guide
View source Open in Colab This guide covers the integration of OpenAI’s Large Language Models (LLMs) with Pinecone (referred to as the OP stack), enhancing semantic search or ‘long-term memory’ for LLMs. This combo utilizes LLMs’ embedding and completion (or generation) endpoints alongside Pinecone’s vector search capabilities for nuanced information retrieval. LLMs like OpenAI’stext-embedding-ada-002 generate vector embeddings, i.e., numerical representations of text semantics. These embeddings facilitate semantic-based rather than literal textual matches. Additionally, LLMs like gpt-4 or gpt-3.5-turbo can predict text completions based on information provided from these contexts.
Pinecone is a vector database designed for storing and querying high-dimensional vectors. It provides fast, efficient semantic search over these vector embeddings.
By integrating OpenAI’s LLMs with Pinecone, we combine deep learning capabilities for embedding generation with efficient vector storage and retrieval. This approach surpasses traditional keyword-based search, offering contextually-aware, precise results.
There are many ways of integrating these two tools and we have several guides focusing on specific use-cases. If you already know what you’d like to do you can jump to these specific materials:
- ChatGPT Plugins Walkthrough
- Ask Lex ChatGPT Plugin
- Generative Question-Answering
- Retrieval Augmentation using LangChain
Introduction to Embeddings
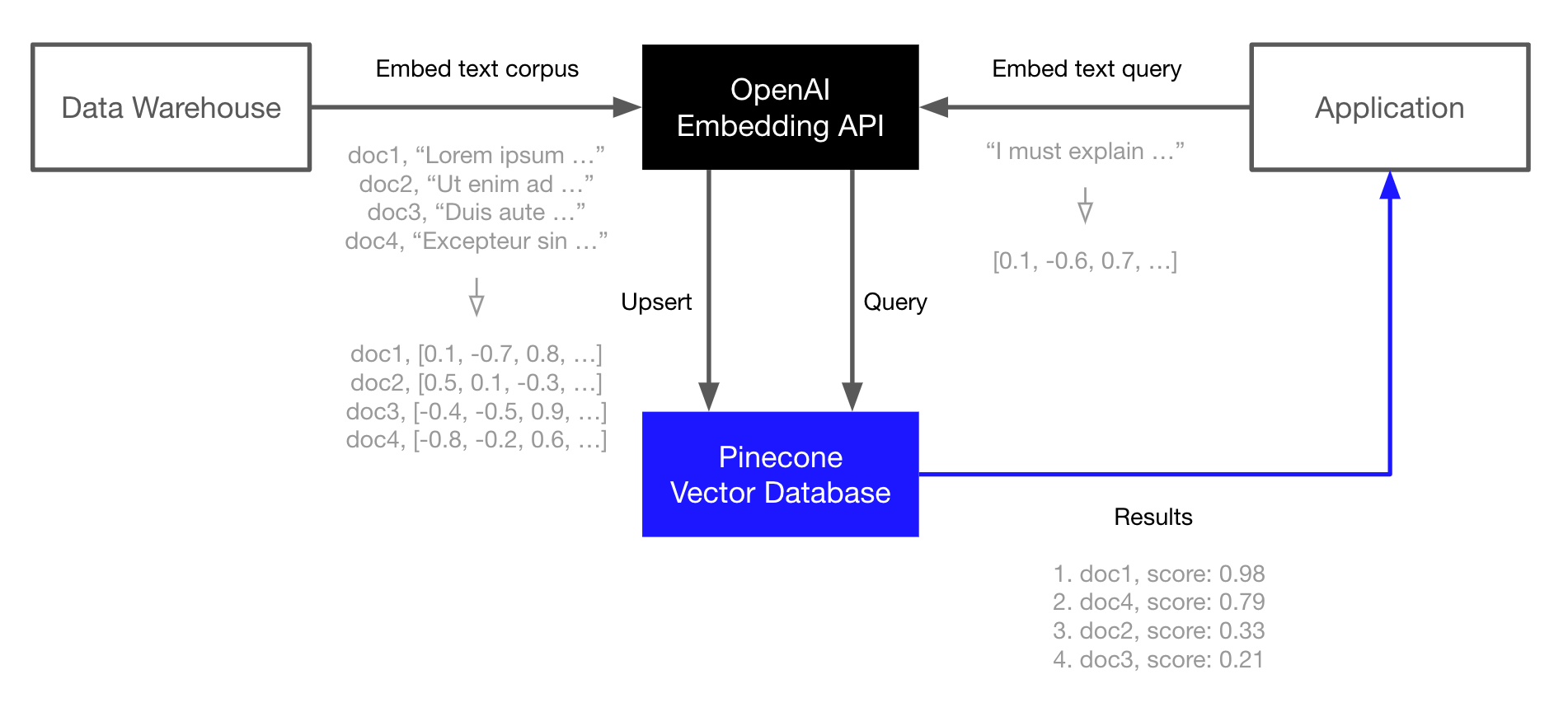
At the core of the OP stack we have embeddings which are supported via the OpenAI Embedding API. We index those embeddings in the Pinecone vector database for fast and scalable retrieval augmentation of our LLMs or other information retrieval use-cases. This example demonstrates the core OP stack. It is the simplest workflow and is present in each of the other workflows, but is not the only way to use the stack. Please see the links above for more advanced usage. The OP stack is built for semantic search, question-answering, threat-detection, and other applications that rely on language models and a large corpus of text data. The basic workflow looks like this:- Embed and index
- Use the OpenAI Embedding API to generate vector embeddings of your documents (or any text data).
- Upload those vector embeddings into Pinecone, which can store and index millions/billions of these vector embeddings, and search through them at ultra-low latencies.
- Search
- Pass your query text or document through the OpenAI Embedding API again.
- Take the resulting vector embedding and send it as a query to Pinecone.
- Get back semantically similar documents, even if they don’t share any keywords with the query.
Environment Setup
We start by installing the OpenAI and Pinecone clients, we will also need HuggingFace Datasets for downloading the TREC dataset that we will use in this guide.Bash
Creating Embeddings
To create embeddings we must first initialize our connection to OpenAI Embeddings, we sign up for an API key at OpenAI.Python
Python
res we should find a JSON-like object containing two 1536-dimensional embeddings, these are the vector representations of the two inputs provided above. To access the embeddings directly we can write:
Python
Initializing a Pinecone Index
Next, we initialize an index to store the vector embeddings. For this we need a Pinecone API key, sign up for one here.Python
Populating the Index
With both OpenAI and Pinecone connections initialized, we can move onto populating the index. For this, we need the TREC dataset.Python
upsert the ID, vector embedding, and original text for each phrase to Pinecone.
Python
Querying
With our data indexed, we’re now ready to move onto performing searches. This follows a similar process to indexing. We start with a textquery, that we would like to use to find similar sentences. As before we encode this with OpenAI’s text similarity Babbage model to create a query vector xq. We then use xq to query the Pinecone index.
Python
Python
metadata field, let’s print out the top_k most similar questions and their respective similarity scores.
Python
Python
Python
Python