For design guidance on choosing between namespaces, metadata filtering, and other approaches, see Design for multi-tenancy.
Namespaces per serverless index vary by plan. On the Standard and Enterprise plans, Pinecone can accommodate million-scale namespaces and beyond for specific use cases. If your application requires more than 100,000 namespaces, contact Support.
How it works
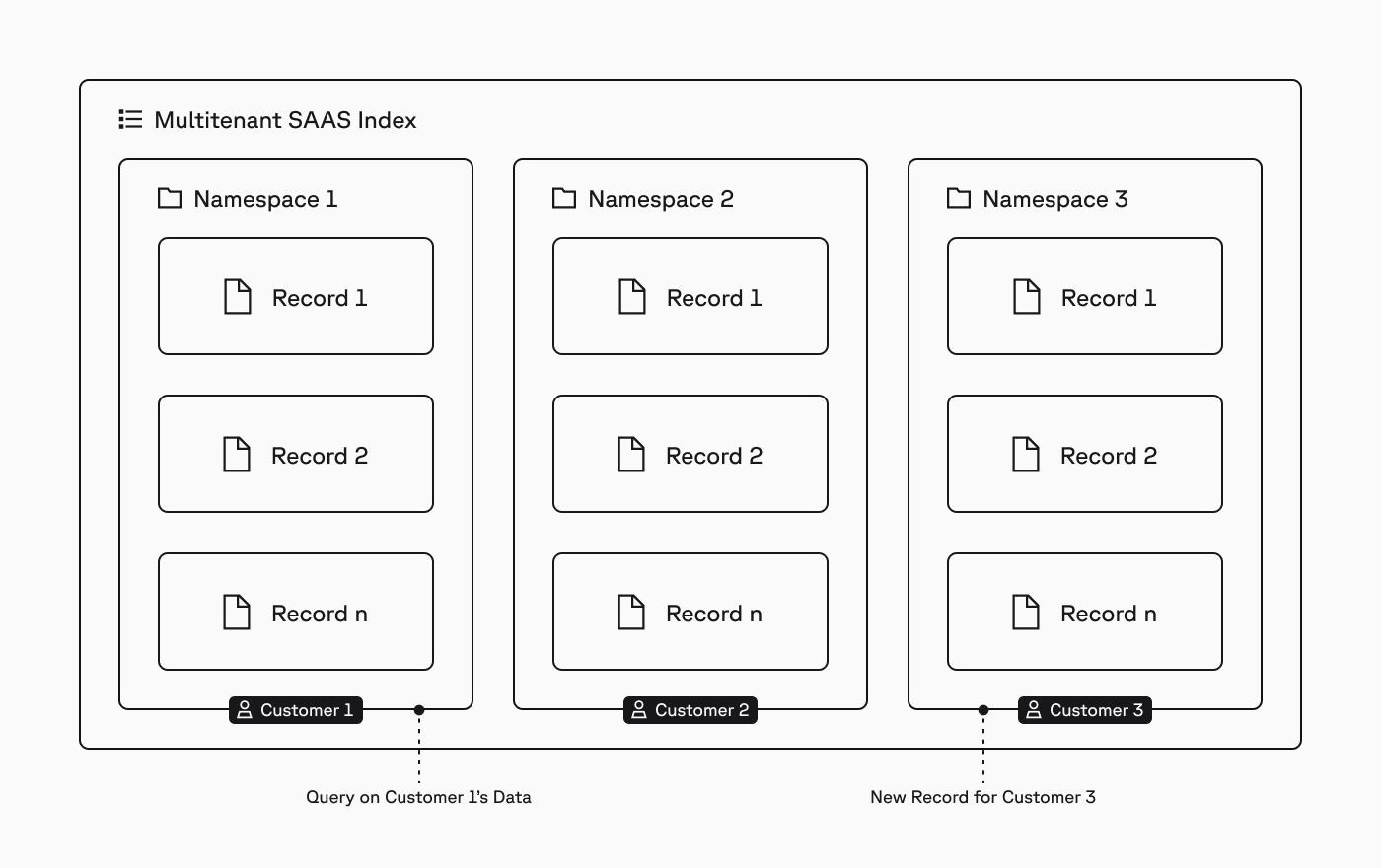
 In Pinecone, an index is the highest-level organizational unit of data, where you define the dimension of vectors to be stored in the index and the measure of similarity to be used when querying the index.
Within an index, records are stored in namespaces, and all upserts, queries, and other data read and write operations always target one namespace.
This structure makes it easy to implement multitenancy. For example, for an AI-powered SaaS application where you need to isolate the data of each customer, you would assign each customer to a namespace and target their writes and queries to that namespace (diagram above).
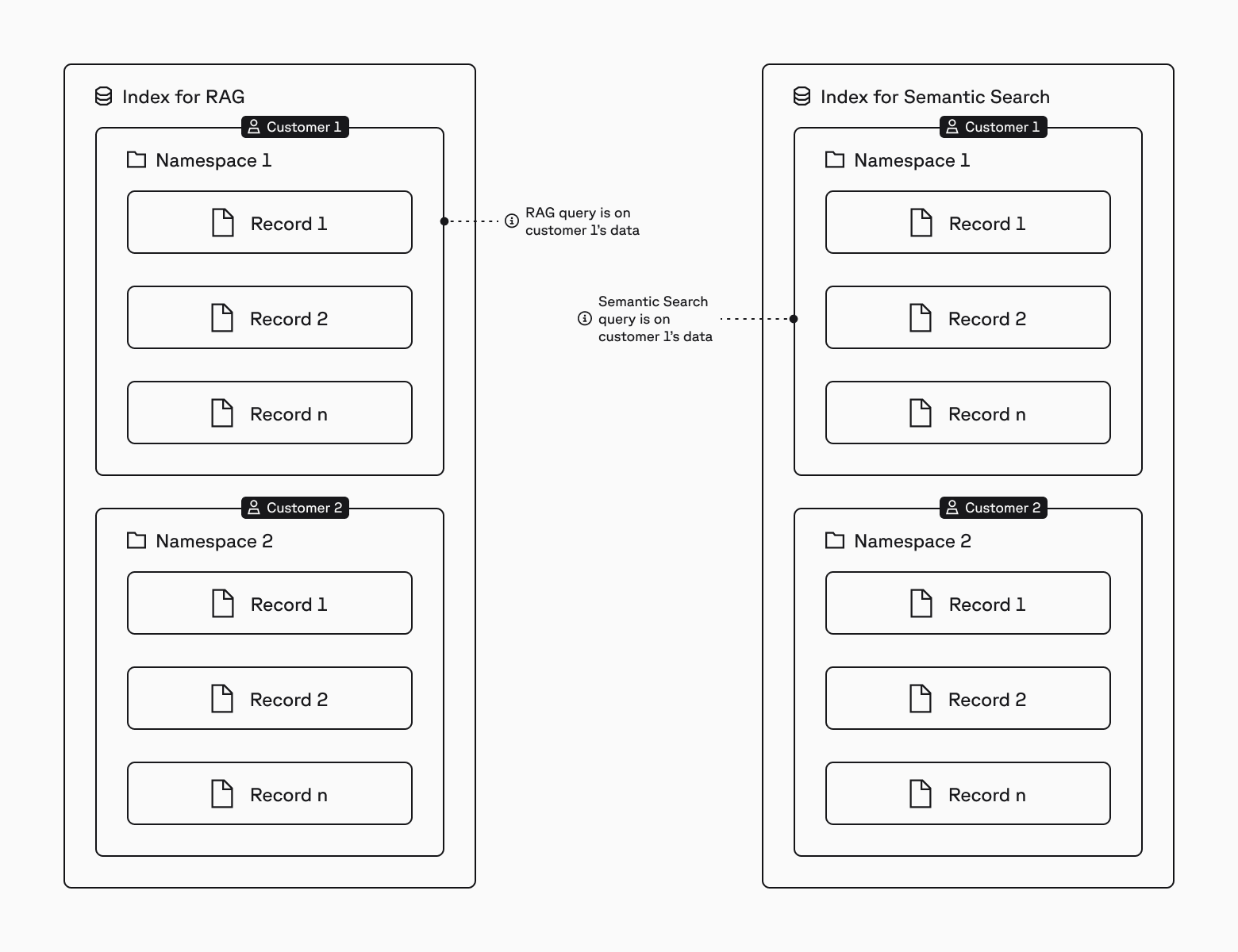
In cases where you have different workload patterns (e.g., RAG and semantic search), you would use a different index for each workload, with one namespace per customer in each index:
In Pinecone, an index is the highest-level organizational unit of data, where you define the dimension of vectors to be stored in the index and the measure of similarity to be used when querying the index.
Within an index, records are stored in namespaces, and all upserts, queries, and other data read and write operations always target one namespace.
This structure makes it easy to implement multitenancy. For example, for an AI-powered SaaS application where you need to isolate the data of each customer, you would assign each customer to a namespace and target their writes and queries to that namespace (diagram above).
In cases where you have different workload patterns (e.g., RAG and semantic search), you would use a different index for each workload, with one namespace per customer in each index:
Understand the benefits
Understand the benefits
- Tenant isolation: In the serverless architecture, each namespace is stored separately, so using namespaces provides physical isolation of data between tenants/customers. This reduces the risk of application bugs that could query the wrong tenant’s data.
- No noisy neighbors: Reads and writes always target a single namespace, so the behavior of one tenant/customer does not affect other tenants/customers.
- No maintenance effort: Serverless indexes scale automatically based on usage; you don’t configure or manage any compute or storage resources.
- Cost efficiency: Query cost is based on namespace size (1 RU per 1 GB). With 100 tenants of 1 GB each, querying one tenant’s namespace costs 1 RU. Using metadata filtering in a single 100 GB namespace would cost 100 RUs for the same query, because it scans all data regardless of filters.
- Simple tenant offboarding: To offboard a tenant/customer, you just delete the relevant namespace. This is a lightweight and almost instant operation.
1. Create a serverless index
Based on a breakthrough architecture, serverless indexes scale automatically based on usage, and you pay only for the amount of data stored and operations performed. Combined with the isolation of tenant data using namespaces (next step), serverless indexes are ideal for multitenant use cases. To create a serverless index, use thespec parameter to define the cloud and region where the index should be deployed. For Python, you also need to import the ServerlessSpec class.
2. Isolate tenant data
In a multitenant solution, you need to isolate data between tenants. To achieve this in Pinecone, use one namespace per tenant. In the serverless architecture, each namespace is stored separately, so this approach ensures physical isolation of each tenant’s data. To create a namespace for a tenant, specify thenamespace parameter when first upserting the tenant’s records. For example, the following code upserts records for tenant1 and tenant2 into the multitenant-app index:
namespace. For example, the following code updates the dense vector value of record A in tenant1:
3. Query tenant data
In a multitenant solution, you need to ensure that the queries of one tenant do not affect the experience of other tenants/customers. To achieve this in Pinecone, target each tenant’s queries at the namespace for the tenant. For example, the following code queries onlytenant2 for the 3 vectors that are most similar to an example query vector:
4. Offboard a tenant
In a multitenant solution, you also need it to be quick and easy to offboard a tenant and delete all of its records. To achieve this in Pinecone, you just delete the namespace for the specific tenant. For example, the following code deletes the namespace and all records fortenant1: