Limitations
Migration is supported for pod-based indexes with less than 25 million records and 20,000 namespaces across all supported clouds (AWS, GCP, and Azure). Also, serverless indexes do not support the following features. If you were using these features for your pod-based index, you will need to adapt your code. If you are blocked by these limitations, contact Pinecone Support.-
Selective metadata indexing
- Because high-cardinality metadata in serverless indexes does not cause high memory utilization, this operation is not relevant.
- Filtering index statistics by metadata
How it works
Migrating a pod-based index to serverless is a 2-step process:1
Save the pod-based index as a collection
2
Create a new serverless index from the collection
1. Understand cost implications
In most cases, migrating to serverless reduces costs significantly. However, costs can increase for read-heavy workloads with more than 1 query per second and for indexes with many records in a single namespace. Before migrating, consider contacting Pinecone Support for help estimating and managing cost implications.2. Prepare for migration
Migrating a pod-based index to serverless can take anywhere from a few minutes to several hours, depending on the size of the index. During that time, you can continue reading from the pod-based index. However, all upserts, updates, and deletes to the pod-based index will not automatically be reflected in the new serverless index, so be sure to prepare in one of the following ways:- Pause write traffic: If downtime is acceptable, pause traffic to the pod-based index before starting migration. After migration, you will start sending traffic to the serverless index.
- Log your writes: If you need to continue reading from the pod-based index during migration, send read traffic to the pod-based index, but log your writes to a temporary location outside of Pinecone (e.g., S3). After migration, you will replay the logged writes to the new serverless index and start sending all traffic to the serverless index.
3. Start migration
- Pinecone console
- API/SDK
-
In the Pinecone console, go to your pod-based index and click the ellipsis (…) menu > Migrate to serverless.
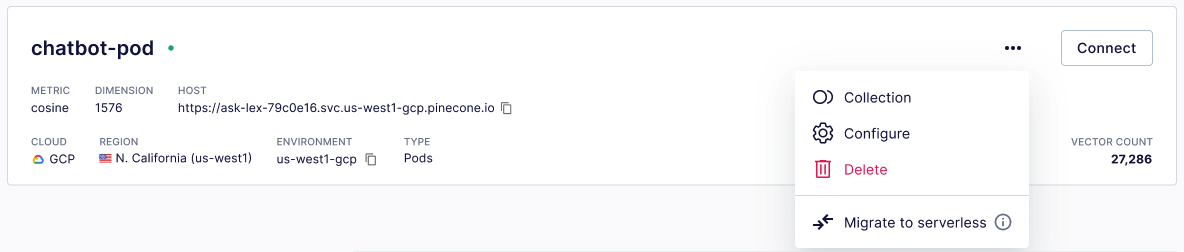 The dropdown will not display Migrate to serverless if the index has any of the listed limitations.
The dropdown will not display Migrate to serverless if the index has any of the listed limitations. -
To save the legacy index and create a new serverless index now, follow the prompts.
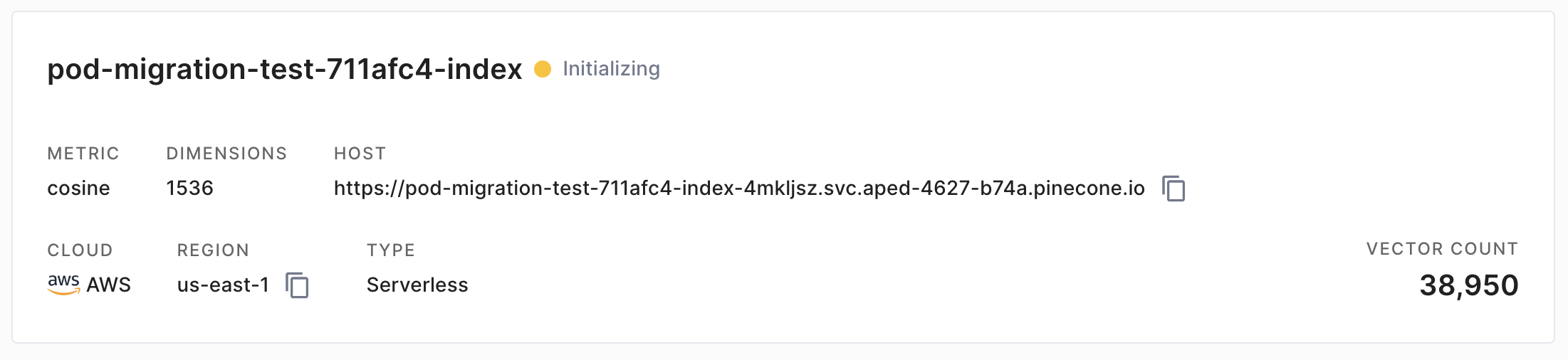
Depending on the size of the index, migration can take anywhere from a few minutes to several hours. While migration is in progress, you’ll see the yellow Initializing status:
4. Update SDKs
If you are using an older version of the Python, Node.js, Java, or Go SDK, you must update the SDK to work with serverless indexes.-
Check your SDK version:
-
If your SDK version is less than 3.0.0 for Python, 2.0.0 for Node.js, 1.0.0 for Java, or 1.0.0 for Go, upgrade the SDK as follows:
5. Adapt existing code
You must make some minor code changes to work with serverless indexes.-
Change how you import the Pinecone library and authenticate and initialize the client:
-
Listing indexes now fetches a complete description of each index. If you were relying on the output of this operation, you’ll need to adapt your code.
The
list_indexesoperation now returns a response like the following: -
Describing an index now returns a description of an index in a different format. It also returns the index host needed to run data plane operations against the index. If you were relying on the output of this operation, you’ll need to adapt your code.
6. Use your new index
When you’re ready to cutover to your new serverless index:-
Your new serverless index has a different name and unique endpoint than your pod-based index. Update your code to target the new serverless index:
- Reinitialize your clients.
- If you logged writes to the pod-based index during migration, replay the logged writes to your serverless index.
- Delete the pod-based index to avoid paying for unused resources.